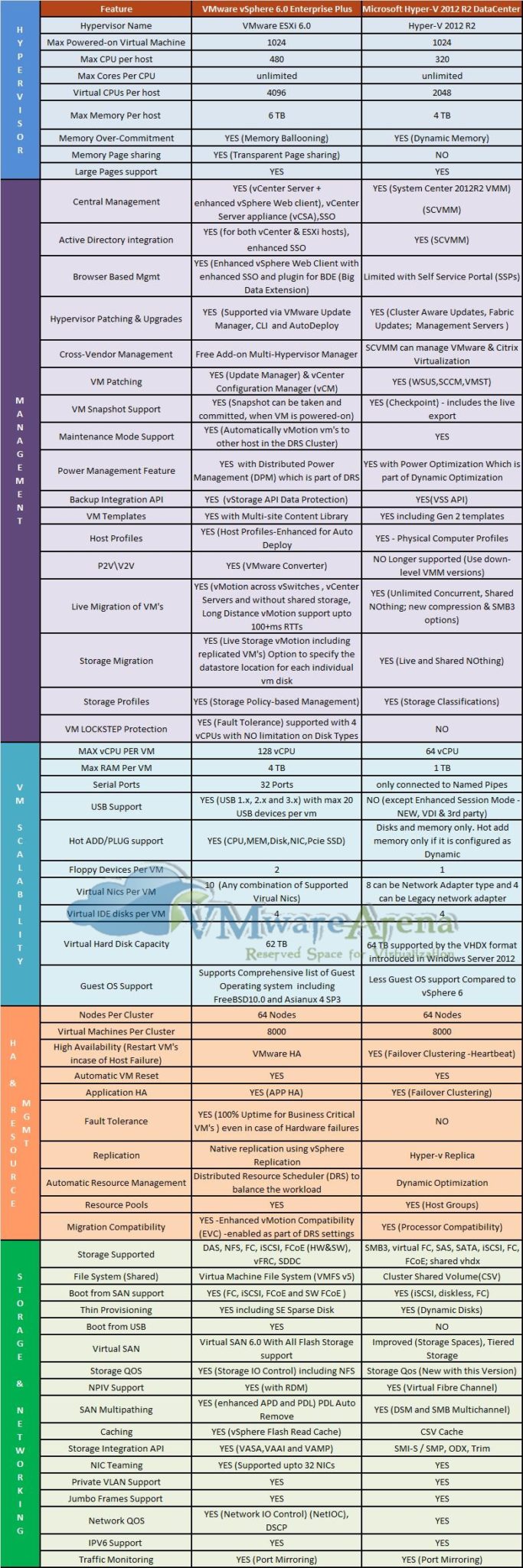
Не так давно на сайте VMwareArena появилось очередное сравнение VMware vSphere (в издании Enterprise Plus) и Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition, которое включает в себя самую актуальную информацию о возможностях обеих платформ.
Мы адаптировали это сравнение в виде таблицы и представляем вашему вниманию ниже:
Группа возможностей
Возможность
VMware vSphere 6
Enterprise Plus
Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition
Возможности гипервизора
Версия гипервизора
VMware ESXi 6.0
Hyper-V 2012 R2
Максимальное число запущенных виртуальных машин
1024
1024
Максимальное число процессоров (CPU) на хост-сервер
480
320
Число ядер на процессор хоста
Не ограничено
Не ограничено
Максимальное число виртуальных процессоров (vCPU) на хост-сервер
4096
2048
Максимальный объем памяти (RAM) на хост-сервер
6 ТБ
4 ТБ
Техники Memory overcommitment (динамическое перераспределение памяти между машинами)
Memory ballooning
Dynamic Memory
Техники дедупликации страниц памяти
Transparent page sharing
Нет
Поддержка больших страниц памяти (Large Memory Pages)
Да
Да
Управление платформой
Централизованное управление
vCenter Server + vSphere Client + vSphere Web Client, а также виртуальный модуль vCenter Server Appliance (vCSA)
System Center Virtual Machine Manager (SC VMM)
Интеграция с Active Directory
Да, как для vCenter, так и для ESXi-хостов через расширенный механизм SSO
Да (через SC VMM)
Поддержка снапшотов (VM Snapshot)
Да, снапшоты могут быть сделаны и удалены для работающих виртуальных машин
Да, технология Checkpoint, включая функции live export
Управление через браузер (тонкий клиент)
Да, полнофункциональный vSphere Web Client
Ограниченное, через Self Service Portal
Обновления хост-серверов / гипервизора
Да, через VMware Update Manager (VUM), Auto Deploy и CLI
Да - Cluster Aware Updates, Fabric Updates, Management Servers
Управление сторонними гипервизорами
Да, бесплатный аддон Multi-Hypervisor Manager
Да, управление VMware vCenter и Citrix XenCenter поддерживается в SC VMM
Обновление (патчинг) виртуальных машин
Да, через VMware Update Manager (VUM) и vCenter Configuration Manager (vCM)
Да (WSUS, SCCM, VMST)
Режим обслуживания (Maintenance Mode)
Да, горячая миграция ВМ в кластере DRS на другие хосты
Да
Динамическое управление питанием
Да, функции Distributed Power Management в составе DRS
Да, функции Power Optimization в составе Dynamic Optimization
API для решений резервного копирования
Да, vStorage API for Data Protection
Да, VSS API
Шаблоны виртуальных машин (VM Templates)
Да + Multi-site content library
Да, включая шаблоны Gen2
Профили настройки хостов (Host Profiles)
Да, расширенные функции host profiles и интеграция с Auto Deploy
Да, функции Physical Computer Profiles
Решение по миграции физических серверов в виртуальные машины
Да, VMware vCenter Converter
Нет, больше не поддерживается
Горячая миграция виртуальных машин
Да, vMotion между хостами, между датацентрами с разными vCenter, Long Distance vMotion (100 ms RTT), возможна без общего хранилища
Да, возможна без общего хранилища (Shared Nothing), поддержка компрессии и SMB3, неограниченное число одновременных миграций
Горячая миграция хранилищ ВМ
Да, Storage vMotion, возможность указать размещение отдельных виртуальных дисков машины
Да
Профили хранилищ
Да, Storage policy-based management
Да, Storage Classifications
Кластер непрерывной доступности ВМ
Да, Fault Tolerance с поддержкой до 4 процессоров ВМ, поддержка различных типов дисков, технология vLockstep
Нет
Конфигурации виртуальных машин
Виртуальных процессоров на ВМ
128 vCPU
64 vCPU
Память на одну ВМ
4 ТБ
1 ТБ
Последовательных портов (serial ports)
32
Только присоединение к named pipes
Поддержка USB
До 20 на одну машину (версии 1,2 и 3)
Нет (за исключением Enhanced Session Mode)
Горячее добавление устройств
(CPU/Memory/Disk/NIC/PCIe SSD)
Только диск и память (память только, если настроена функция Dynamic memory)
Диски, растущие по мере наполнения данными (thin provisioning)
Да (thin disk и se sparse)
Да, Dynamic disks
Поддержка Boot from USB
Да
Нет
Хранилища на базе локальных дисков серверов
VMware Virtual SAN 6.0 с поддержкой конфигураций All Flash
Storage Spaces, Tiered Storage
Уровни обслуживания для подсистемы ввода-вывода
Да, Storage IO Control (работает и для NFS)
Да, Storage QoS
Поддержка NPIV
Да (для RDM-устройств)
Да (Virtual Fibre Channel)
Поддержка доступа по нескольким путям (multipathing)
Да, включая расширенную поддержку статусов APD и PDL
Да (DSM и SMB Multichannel)
Техники кэширования
Да, vSphere Flash Read Cache
Да, CSV Cache
API для интеграции с хранилищами
Да, широкий спектр VASA+VAAI+VAMP
Да, SMI-S / SMP, ODX, Trim
Поддержка NIC Teaming
Да, до 32 адаптеров
Да
Поддержка Private VLAN
Да
Да
Поддержка Jumbo Frames
Да
Да
Поддержка Network QoS
Да, NetIOC (Network IO Control), DSCP
Да
Поддержка IPv6
Да
Да
Мониторинг трафика
Да, Port mirroring
Да, Port mirroring
Подводя итог, скажем, что нужно смотреть не только на состав функций той или иной платформы виртуализации, но и необходимо изучить, как именно эти функции реализованы, так как не всегда реализация какой-то возможности позволит вам использовать ее в производственной среде ввиду различных ограничений. Кроме того, обязательно нужно смотреть, какие функции предоставляются другими продуктами от данного вендора, и способны ли они дополнить отсутствующие возможности (а также сколько это стоит). В общем, как всегда - дьявол в деталях.
Компания VMware выпустила первое после нового года обновление своей серверной платформы виртуализации - VMware vSphere 6.0 Update 1b, включая обновления vCenter и ESXi.
Новых возможностей, конечно же, немного, но все же компоненты vSphere рекомендуется обновить ввиду наличия критичных обновлений подсистемы безопасности.
Что нового в VMware vCenter Server 6.0 Update 1b:
Поддержка метода обновления URL-based patching с использованием zip-пакета. Подробнее в KB 2142009.
Пользовательские настройки для Client Integration Plugin или диалогового окна VMware-csd guard в vSphere Web Client могут быть переопределены. Подробнее в KB 2142218.
vSphere 6.0 Update 1b включает поддержку TLS версий 1.1 и 1.2 для большинства компонентов vSphere без нарушения совместимости с предыдущими версиями. Компоненты которые по-прежнему поддерживают только TLS версии 1.0:
vSphere Client
Virtual SAN Observer на сервере vCenter Server Appliance (vCSA)
Syslog на сервере vCSA
Auto Deploy на vCSA
Auto Deploy на iPXE
О поддержке TLS-протоколов можно почитать подробнее в KB 2136185 .
Утилита certificate manager теперь автоматически вызывает скрипт updateExtensionCertInVC.py для обновления хранилищ сертификатов, которые построены не на базе VMware Endpoint Certificate Store (VECS).
Множество исправлений ошибок.
Что нового в VMware ESXi 6.0 Update 1b:
Поддержка TLS версий 1.1 и 1.2 для большинства компонентов без нарушения совместимости с предыдущими версиями.
Поддержка Advanced Encryption Standard (AES) с длиной ключа 128/256 бит для аутентификации через NFS 4.1 Client.
Исправления ошибок.
Скачать VMware vCenter Server 6.0 Update 1b и VMware ESXi 6.0 Update 1b можно по этой ссылке.
Это гостевой пост сервис-провайдера 1cloud, предоставляющего услуги облачной аренды виртуальных машин. Ранее они рассказывали о развитии данной технологии в статье о «революции контейнеров» в своем блоге на Хабре.
Шумиха вокруг контейнеров последнего времени поставила один важный вопрос: как эта технология сможет ужиться с традиционными вариантами управления инфраструктурой, и какие угрозы она таит для рынка виртуализации? И даже более конкретный: заменят ли контейнеры виртуальные машины?
На ежегодной конференции в Сан-Франциско, прошедшей на в сентябре 2015 года, VMware дала однозначно понять, что этого не произойдет. Новая платформа управления вводит новый тип виртуализации — для самих контейнеров.
Виртуализация для контейнеров
Полтора десятка лет назад VMware взорвала технологическую индустрию, выпустив свой корпоративный гипервизор, открывший эпоху серверной виртуализации. На прошлой неделе компания представила обновленную версию своей классической программы для виртуализации под названием Project Photon. По сути, это облегченная реплика популярного гипервизора ESX компании, разработанная специально для работы с приложениями в контейнерной реализации.
«В ее основе, по-прежнему, лежит принцип виртуализации», — объясняет вице-президент VMware и технический директор Cloud Native Applications Кит Колберт. Он предпочитает называть Photon «микровизором» с достаточным набором функций для успешной виртуализации, упакованный в удобный для контейнеров формат.
Project Photon состоит из двух ключевых элементов. Photon Machine – оболочка для гипервизора, дублирующая ESX и устанавливаемая напрямую на физические серверы. Она создает виртуальную машину в миниатюре, куда помещаются контейнеры. Пользователь может самостоятельно выбрать гостевую ОС. По умолчанию устанавливается Photon ОС под Linux, которую компания также сделала совместимой с технологией контейнеров.
Второй элемент – это Photon Controller, мультитенантный маршрутизатор, позволяющий управлять одновременно дюжинами, если не тысячами, объектов на Photon Machine. Он следит за тем, чтобы все блоки (кластеры) Photon Machine имели доступ к сети и базам данных, когда это необходимо.
Комбинация этих двух элементов задает шаблон для масштабируемой среды и имеет надстройку для написания API. В теории, IT-операторы могу усовершенствовать Project Photon, и сами разработчики создавать на его базе приложения.
Project Photon способен интегрироваться с открытыми программами. Например, с Docker’ом для поддержки исполнения программы, или с Google Kubernetes и Pivotil’s Cloud Foundry для более качественного управления приложениями. Photon в данном случае выполняет подготовку инфраструктуры, а Kubernetes и CF занимаются развертыванием приложений.
В прошлом году для индивидуальных пользователей платформа стала доступна в качестве бета-версии.
Долгая дорога к контейнерам
Не все пользователи готовы полностью переключиться на контейнерную реализацию. Поэтому VMware для сомневающихся интегрирует поддержку контейнеров с традиционными инструментами управления.
vSphere Integrated Containers – еще один продукт, анонсированный на конференции. Как пояснил Кит Колберт, это идеальный вариант для тех, кто только хочет начать экспериментировать с контейнерами. Для желающих же использовать возможности контейнеров по максимуму он рекомендует переход к Project Photon.
vSphere Integrated Containers представляет собой плагин для vSphere, установленной на достопочтенном ESX компании. «Он делает контейнеры самыми желанными гостями платформы», — уточняет Колберт. При помощи плагина пользователи могут устанавливать контейнеры внутрь виртуальной машины, позволяя управлять ею так же, как и любой другой в пространстве платформы виртуализации.
В текущих условиях, если пользователь решил загрузить контейнеры в vSphere, ему приходится все скопом помещать их в одну единственную виртуальную машину. Таким образом, если что-то случится с одним из контейнеров, повреждения могут получить и все остальные, находящиеся в ВМ. Распределение контейнеров по разным ВМ обеспечивает их сохранность и аккуратное управление платформой.
Аналитик Marko Insights Курт Марко говорит, что новый подход к контейнерной реализации VMware должен облегчить жизнь и самим администраторам платформы. «Работа с контейнерами Photon в формате микро-ВМ схожа с тем, как работают с классом стеков и операторов, — сообщает Марко в своем письме. – Конечно, здесь могут быть потери в производительности, поскольку даже микро-ВМ будут больше перегружены, чем контейнеры, пользующиеся одними ядрами и библиотеками. В самой VMware утверждает, что это проблемой можно пренебречь, но Марко настаивает на независимом анализе издержек работы с контейнерами внутри виртуальных машин.
Не все так быстро
В VMware полны энтузиазма и рассматривают себя в качестве флагмана контейнерной реализации. Но есть несколько моментов, способных этот порыв охладить. Во-первых, вероятно, рынок контейнеров еще к этому не готов.
«Реклама продукта пока обгоняет реальность», — говорит аналитик IDC Эл Гиллен. По его подсчетам, менее десятой доли процента корпоративных приложений сейчас делаются через контейнеры. Может пройти десятилетие, пока рынок переварит эти технологии, и цифра приблизится к 40%.
Во-вторых, VMware никогда не обладала репутацией компании, готовой быть в авангарде разработок открытого программного обеспечения и проектов. Скорее, наоборот. Соучредитель и исполнительный директор Rancher Labs (стартапа, внедрившего свою ОС для контейнеров на VMworld) Шен Льян говорит, что до этого момента контейнерную реализацию продвигали сами разработчики или открытые платформы, наподобие Mesos, Docker и Kubernetes. Он добавил, что не встречал еще ни одного человека, использующего в работе контейнеры, который бы делал это с помощью инструментария VMware.
Аналитик Forrester Дейв Бартолти не удивлен данному обстоятельству. В VMware налажены прочные связи с проектными ИТ-менеджерами, но не с разработчиками, активно использующими контейнеры. Новинки, которые компания представила на VMworld, должны как раз вдохновить первых активно использовать контейнеры в рамках работы с платформой VMware. Остальные вендоры, среди которых Red Hat, Microsoft и IBM, также с удовольствием пользуются этой процедурой. VMware настаивает, что нашла способ примерить виртуальные машины и контейнеры.
Продолжаем рассказывать о решении номер 1 для создания программных хранилищ под виртуализацию VMware и Microsoft - StarWind Virtual SAN. Сегодня мы расскажем о том, как корректно настроить механизм доступа к хранилищам по нескольким путям MPIO (Multi-Path Input/Output) на сервере хранения Windows Server 2012.
Сначала необходимо убедиться, что возможность MPIO установлена на сервере, и, если нет, то установить ее:
Открываем Server Manager.
Нажимаем кнопку "Manage" в правом верхнем углу и выбираем "Add Roles and Features".
Нажимаем Next в первой странице мастера.
В части Installation Type выбираем "Role-based or feature-based installation".
На странице Server Selection выбираем нужный сервер, где хотим включить MPIO (по умолчанию этот сервер).
В разделе Features отмечаем галкой "Multipath I/O" и жмем кнопку "Install".
После того, как вы добавили возможность MPIO на Windows Server, нужно включить ее поддержку для iSCSI-устройств, которые использует StarWind Virtual SAN:
Откройте настройку MPIO в средствах администрирования сервера.
Нажмите на вкладку "Discover Multi-Paths".
Поставьте галочку напротив "Add support for iSCSI devices".
Перезагрузите сервер.
Затем нужно настроить политику доступа по нескольким путям. StarWind рекомендует использовать политику "Fail Over Only", если сумма пропускных способностей ваших путей составляет менее 10 Гбит/с. В противном случае стоит использовать политику Round Robin в целях повышения производительности.
Более подробно о настройке MPIO для StarWind рассказано тут.
Как вы знаете, в новой версии решения VMware Horizon 6.2 для виртуализации настольных ПК компания VMware сделала специальное издание VMware Horizon for Linux, позволяющее создавать инфраструктуру виртуальных десктопов на базе компьютеров с хостовой ОС Linux. Это востребовано в организациях, где такие рабочие станции используются для графического моделирования, сложных расчетов и прочих требовательных к производительности графической подсистемы нагрузок.
Напомним, что еще с версии Horizon 6.2 полностью поддерживались режимы Virtual Shared Graphics Acceleration (vSGA), Virtual Dedicated Graphics Acceleration (vDGA) и NVIDIA GRID vGPU на базе GRID 2.0 для Linux-десктопов:
Дистрибутив Linux
Режимы работы 3D-графики
vSGA
vDGA
vGPU
Red Hat Enterprise Linux 6.6 Workstation x86_64
Нет
Horizon 6.1.1 или более поздний
Требует адаптера NVIDIA M60, GRID 2.0, а также Horizon 6.2 или более поздний
Red Hat Enterprise Linux 7.1 Workstation x86_64
Horizon 6.2 или более поздний
Нет
Требует адаптера NVIDIA M60, GRID 2.0, а также Horizon 6.2 или более поздний
Совсем недавно компания VMware выпустила VMware Horizon 6.2.1, где в плане поддержки Linux-десктопов появилось еще несколько нужных новых возможностей:
1. Clipboard Redirection (Copy / Paste).
Теперь в Linux-десктопах появилось перенаправление клавиатуры, которое позволяет копировать и вставлять из хостового ПК в виртуальный и обратно текст с форматированием, а также картинки. Естественно, в целях безопасности можно эту функцию отключить в файле конфигурации /etc/vmware/config (см. документ "Setting Up Horizon 6 for Linux Desktops").
2. Single Sign-On.
Теперь в Linux-ПК появилась поддержка SSO, позволяющая пользователю хостового устройства не вводить учетные данные при логине в свой виртуальный ПК Linux, который интегрирован со службами Active Directory через Open LDAP. Эти возможности поддерживаются для Horizon Client под Mac, Windows и Linux. На данный момент функция доступна только для ПК Red Hat Enterprise Linux 6.6 Workstation x86_64 и CentOS 6.6 x86_64.
3. Smart Card Authentication.
Аутентификация через смарт-карты в виртуальном ПК требуется во многих государственных и частных организациях с соответствующими регулирующими процедурами. Для аутентификации поддерживаются карты типа Personal Identity Verification (PIV) и Common Access Cards (CAC) с дистрибутивом Red Hat Enterprise Linux 6.6 Workstation x86_64.
4. Kerberos Authentication
После установки View Agent в виртуальный ПК Linux вы можете выбрать тип аутентификации Kerberos в дополнение к уже имеющейся MD5 digest authentication.
5. Consolidated Client Environment Information
До VMware Horizon 6.2.1 вся информация о пользовательском окружении (имя хоста, IP-адрес и прочее) записывалась в стандартный лог-файл, содержащий отладочную информацию. Это было неудобно, так как файл большой, и выуживать из него нужные данные было тяжело. Теперь для этого есть отдельный файл /var/log/vmware/Environment.txt, который поможет решать проблемы при настройке инфраструктуры виртуальных ПК.
Получить VMware Horizon 6.2.1 for Linux можно двумя способами:
1. Купить лицензию VMware Horizon 6 Enterprise Edition, которая содержит все необходимое для построения VDI-инфраструктуры, в том числе на Linux-платформе.
2. Использовать специализированное издание Horizon 6 for Linux standalone, которое можно скачать по этой ссылке.
Иногда системному администратору VMware vSphere требуется узнать, сколько тот или иной хост ESXi работает с момента последней загрузки (например, требуется проверить, не было ли внеплановых ребутов).
Есть аж целых 5 способов сделать это, каждый из них можно применять в зависимости от ситуации.
1. Самый простой - команда uptime.
Просто заходим на хост ESXi из консоли или по SSH и выполняем команду uptime:
login as: root
Using keyboard-interactive authentication.
Password: XXXXXX
The time and date of this login have been sent to the system logs.
VMware offers supported, powerful system administration tools. Please
see www.vmware.com/go/sysadmintools for details.
The ESXi Shell can be disabled by an administrative user. See the
vSphere Security documentation for more information.
~ # uptime
04:26:24 up 00:20:42, load average: 0.01, 0.01, 0.01
2. С помощью команды esxtop.
С помощью утилиты esxtop можно не только отслеживать производительность хоста в различных аспектах, но и узнать его аптайм. Обратите внимание на самую первую строчку вывода:
# esxtop
4. Время запуска хоста из лога vmksummary.log.
Вы можете посмотреть не только время текущего аптайма хоста ESXi, но времена его прошлых запусков в логе vmksummary.log. Для этого выполните следующую команду:
cat /var/log/vmksummary.log |grep booted
2015-06-26T06:25:27Z bootstop: Host has booted
2015-06-26T06:47:23Z bootstop: Host has booted
2015-06-26T06:58:19Z bootstop: Host has booted
2015-06-26T07:05:26Z bootstop: Host has booted
2015-06-26T07:09:50Z bootstop: Host has booted
2015-07-08T05:32:17Z bootstop: Host has booted
4. Аптайм в vSphere Client и Web Client.
Если вы хотите вывести аптайм сразу всех виртуальных машин на хосте в VMware vSphere Client, для этого есть специальная колонка в представлении Hosts:
5. Аптайм хостов через PowerCLI.
Конечно же, время работы хоста ESXi можно посмотреть и через интерфейс PowerCLI. Для этого нужно воспользоваться командлетом Get-VMHost:
В новой книге Фрэнка на 300 страницах раскрываются следующие моменты, касающиеся производительности подсистемы хранения платформ виртуализации, построенной на базе локальных дисков хост-серверов:
Новая парадигма построения виртуального датацентра с точки зрения систем хранения
Архитектура решения FVP
Ускорение доступа к данным
Технология непрерывной доступности Fault Tolerance
Технология Flash
Техники доступа к памяти
Настройка кластера решения FVP
Сетевой дизайн инфраструктуры локальных хранилищ
Внедрение и пробная версия решения FVP
Дизайн инфраструктуры хранилищ
Несмотря на то, что книга рассматривает в качестве основного продукта решение FVP от компании PernixData, ее интересно читать и с точки зрения понимания архитектуры и производительности подобных решений.
От лица всего коллектива VM Guru, его авторов и волонтеров, поздравляю наших читателей и партнеров с Новым 2016 годом! В следующем году желаю вам бывать больше с семьей, найти и сохранить любовь, достичь профессиональных успехов и осуществить, по крайней мере, одну большую мечту!
Все вам самого доброго и теплого в новом году! Пусть все невзгоды и плохие люди обойдут вас стороной. Оставайтесь с нами - в следующем году у нас будет много интересного. Спасибо, что читаете нас.
Компания VMware выпустила интересную инфографику, наглядно представляющую распреление сертифицированных специалистов VMware Certified Professionals (VCP) по регионам мира. 70% стран мира имеют хотя бы одного VCP, а в 46% стран их больше, чем 50 (картинка кликабельна):
Интересно также и то, что 38% VCP имеют более, чем одну сертификацию (видимо, имеется в виду сертификация именно VMware).
Судя по всему, у нас VCP почти столько же, сколько, например, в ЮАР. Это прискорбно - посмотрите на Индию или Австралию, к примеру, и оцените разницу в масштабах.
Какое-то время назад мы писали о технологии доставки приложений пользователям инфраструктуры настольных ПК предприятия - VMware App Volumes (ранее это называлось Cloud Volumes). Суть ее заключается в том, что виртуализованные и готовые к использованию приложения VMware ThinApp доставляются пользователям в виде подключаемых виртуальных дисков к машинам.
Недавно компания VMware выпустила документ "VMware App Volumes Reference Architecture", в котором объясняется работа технологии App Volumes, рассматривается референсная архитектура этого решения, а также проводится тестирование производительности доставляемых таким образом приложений по сравнению с их нативной установкой внутри виртуальных ПК:
Собственно, типовая архитектура решения App Volumes выглядит следующим образом:
Здесь показаны основные компоненты такой инфраструктуры:
AppStacks - это тома, которые содержат сами установленные приложения и работают в режиме Read Only. Их можно назначить пользователям Active Directory, группам или OU. Один такой диск может быть назначен сразу нескольким виртуальным ПК (по умолчанию доступен всем машинам датацентра).
Writable Volumes - это персонализированные тома, которые принадлежат пользователям. Они хранят настройки приложений, лицензионную информацию, файлы конфигураций приложений и сами приложения, которые пользователь установил самостоятельно. Один такой диск может быть назначен только одному десктопу, но его можно перемещать между десктопами.
App Volumes Manager Server - это Windows-сервер, содержащий административную консоль для настройки продукта и управления им.
В качестве референсной архитектуры используется инфраструктура из 2000 виртуальных ПК, запущенных на 18 хостах ESXi инфраструктуры VMware Horizon View:
Для генерации нагрузки использовались различные сценарии пользовательского поведения, создаваемые с помощью средства Login VSI, ставшего уже стандартом де-факто для тестирования VDI-инфраструктур, развернутого на трех хост-серверах.
Здесь описаны 3 варианта тестирования:
Приложения, нативно установленные в виртуальных ПК.
Приложения App Volumes, использующие один AppStack, содержащий основные приложения пользователей.
Приложения App Volumes, распределенные по трем различным AppStack.
Для обоих случаев тестирования App Volumes использовался один Writable Volume. Тут были получены следующие результаты (больше очков - это лучше).
Посмотрим на время логина пользователей при увеличении числа одновременных сессий в референсной архитектуре:
Взглянем на время отклика приложений:
Оценим время запуска приложений:
В целом-то, нельзя сказать, что потери производительности незначительные - они, безусловно, чувствуются. Но радует, что они фиксированы и хорошо масштабируются при увеличении числа одновременных сессий в VDI-инфраструктуре.
Документ очень полезен для оценки потерь производительности с точки зрения User Experience при использовании App Volumes по сравнению с традиционной доставкой приложений. Скачать 50-страничный документ можно скачать по этой ссылке - почитайте, там действительно интересно все изложено.
Если вы посмотрите в документ VSAN Troubleshooting Reference Manual (кстати, очень нужный и полезный), описывающий решение проблем в отказоустойчивом кластере VMware Virtual SAN, то обнаружите там такую расширенную настройку, как VSAN.ClomMaxComponentSizeGB.
Когда кластер VSAN хранит объекты с данными виртуальных дисков машин, он разбивает их на кусочки, растущие по мере наполнения (тонкие диски) до размера, указанного в данном параметре. По умолчанию он равен 255 ГБ, и это значит, что если у вас физические диски дают полезную емкость меньше данного объема (а точнее самый маленький из дисков в группе), то при достижении тонким диском объекта предела физической емкости вы получите вот такое сообщение:
There is no more space for virtual disk XX. You might be able to continue this session by freeing disk space on the relevant volume and clicking retry.
Если, например, у вас физический диск на 200 ГБ, а параметры FTT и SW равны единице, то максимально объект виртуального диска машины вырастет до этого размера и выдаст ошибку. В этом случае имеет смысл выставить настройку VSAN.ClomMaxComponentSizeGB на уровне не более 80% емкости физического диска (то есть, в рассмотренном случае 160 ГБ). Настройку эту нужно будет применить на каждом из хостов кластера Virtual SAN.
Как это сделать (более подробно об этом - в KB 2080503):
В vSphere Web Client идем на вкладку Manage и кликаем на Settings.
Под категорией System нажимаем Advanced System Settings.
Выбираем элемент VSAN.ClomMaxComponentSizeGB и нажимаем иконку Edit.
Устанавливаем нужное значение.
Надо отметить, что изменение этой настройки работает только для кластера VSAN без развернутых на нем виртуальных машин. Если же у вас уже продакшен-инфраструктура столкнулась с такими трудностями, то вы можете воспользоваться следующими двумя способами для обхода описанной проблемы:
1. Задать Object Space Reservation в политике хранения (VM Storage Policy) таким образом, чтобы дисковое пространство под объекты резервировалось сразу (на уровне 100%). И тогда VMDK-диски будут аллоцироваться целиком и распределяться по физическим носителям по мере необходимости.
2. Задать параметр Stripe Width в политиках VM Storage Policy таким образом, чтобы объекты VMDK распределялись сразу по нескольким физическим накопителям.
Фишка еще в том, что параметрVSAN.ClomMaxComponentSizeGB не может быть выставлен в значение, меньшее чем 180 ГБ, а значит если у вас носители меньшего размера (например, All-Flash конфигурация с дисками меньше чем 200 ГБ) - придется воспользоваться одним из этих двух способов, чтобы избежать описанной ошибки. Для флеш-дисков 200 ГБ установка значения в 180 ГБ будет ок, несмотря на то, что это уже 90% физической емкости.
«За выдающийся вклад технического партнера в продвижение серверных систем NetApp» — такую награду получила компания ИТ-ГРАД, предоставляющая услуги хостинга виртуальных машин, на специальном мероприятии NetApp Insight 2015 в Германии. Комментарий от компании ИТ-ГРАД:
Для нас это несколько больше, чем просто еще одна красивая стеклянная фигурка. Как известно многим нашим заказчикам, ИТ-ГРАД не только предоставляет услуги по облачному хостингу в модели IaaS, но и поставляет системы хранения данных, серверное и сетевое оборудование. Вне зависимости от того, собираетесь ли вы модернизировать свою ИТ-инфраструктуру или разработать собственное облако (почему бы и нет?) – у нас вы всегда сможете получить грамотную консультацию и заказать необходимое оборудование.
В качестве СХД мы сами используем хранилища NetApp FAS и рекомендуем их заказчикам с такими же высокими требованиями к надежности и производительности. ИТ-ГРАД не просто продает серверное оборудование, но и осуществляет техническую поддержку по самым разным техническим вопросам. Многолетний собственный опыт и регулярное повышение квалификации инженеров – это наш залог успешного внедрения и эксплуатации корпоративных систем.
За последние годы наше предложение по хранилищам NetApp перешло из разряда дополнительной деятельности в активно развивающееся направление, с хорошим ростом продаж. Настолько хорошим, что статистику оценил сам вендор и включил нас в список лучших российских поставщиков систем хранения NetApp.
Те из вас, кто использовал решение для обеспечения высокой доступности хранилищ под виртуализацию StarWind Virtual SAN, знают, что в продукте предусмотрена возможность асинхронной репликации данных на резервный узел для обеспечения катастрофоустойчивости. В этом случае на резервную площадку откидывается снапшот данных основного узла по заданному администратором расписанию.
В документе приведены как общие сведения об устройстве механизма асинхронной репликации данных StarWind Virtual SAN, так и подробные пошаговые инструкции по его настройке. Также советуем посмотреть еще один документ StarWind об асинхронной репликации.
Пару месяцев назад мы писали о том, что вышло обновление VMware vSphere 5.5 Update 3, которое полезно для пользователей, еще не перешедших на обновленную версию платформы виртуализации vSphere 6.
Новых возможностей там было немного, поэтому многие проигнорировали этот апдейт - а зря. Там появилось множество улучшений производительности операций в Web Client, о чем у VMware есть отдельная статья. Приведем основную выжимку здесь.
Как вы знаете, в vSphere Web Client 6.0 был сделан шаг вперед в плане улучшения производительности, а сейчас инженеры VMware портировали эти изменения уже на младшую версию vSphere 5.5 U3. При этом, по оценке самой VMware, теперь производительность тонкого клиента в этой версии в некоторых аспектах аналогична оной в vSphere 6.0 Update 1.
Улучшения были сделаны в следующих областях:
Меню действий и меню по правому клику мыши
Страницы Related Objects, Summary и Settings
Мастера выполнения операций (миграция, создание шаблона и т.п.)
Процесс логина в консоль
Графики отображения производительности
Для тестирования сделанных улучшений (VMware уверяет, что их было сделано очень много) использовались 2 типа окружения:
Большое – vCenter Server (32 vCPU / 64 GB RAM), 1000 хостов, 15000 ВМ
Посмотрим на время логина в Web Client:
Уменьшилось ровно в 2 раза. Теперь посмотрим на отклик меню действий (оно же вызывается по правой кнопке мыши):
Здесь кое-где и в 3 раза улучшилась ситуация. Для меню виртуальных машин ситуация не сильно улучшилась, так как в этом меню большое количество контекстно-зависимых действий.
Генерация графиков производительности (выбор объектов, ресайз графиков, обновление, выбор элементов для отображения). Здесь очень существенные улучшения, более чем в 2 раза:
Отображение связанных объектов, например, вы выбираете кластер и отображения списка виртуальных машин в нем происходит намного быстрее:
В общем, если вы еще не обновились - причина поставить новую версию Web Client есть.
Для тех из вас, кто использует в производственной среде или тестирует решение VMware NSX для виртуализации сетей своего датацентра, компания VMware подготовила полезный документ "VMware NSX for vSphere Network Virtualization Design Guide", который вышел уже аж в третьей редакции.
Документ представляет собой рефернсный дизайн инфраструктуры виртуализации сетей в датацентре и описывает архитектуру решения NSX на физическом и логическом уровнях.
В новой версии документа появилась следующая информация для сетевых архитекторов:
сайзинг решения NSX для небольших датацентров
лучшие практики маршрутизации
микросегментация и архитектура компонента обеспечения безопасности среды Service Composer
Документ содержит ни много ни мало 167 страниц. Скачать его можно по этой ссылке.
Мы уже не раз писали про веб-консоль управления ESXi Embedded Host Client, которая доступна на сайте проекта VMware Labs как VIB-пакет для вашего сервера ESXi. Вот тут мы писали о возможностях третьей версии, а на днях стал доступен обновленный ESXi Embedded Host Client v4.
Давайте посмотрим на его новые возможности.
Основное:
Новое меню Tools and links под разделом Help.
Механизм обновления теперь принимает URL или путь к хранилищу с zip-файлом метаданных, что позволяет обновлять собственно сам сервер ESXi, а не только накатывать VIB-пакеты. Подробнее об этом тут.
Локализация и интернационализация (французский, испанский, японский, немецкий, китайский и корейский).
Возможность отключить таймаут сессии (очен удобно, если клиент всегда открыт у вас на вкладке браузера).
Большое количество исправлений ошибок и мелких улучшений.
Операции с виртуальными машинами:
Работа со списком виртуальных машин была оптимизирована по производительности.
Возможность изменять расширенные настройки ВМ (advanced settings).
Возможность изменять настройки видеоадаптера ВМ.
Добавление девайса PCI pass-through (и его удаление).
Поддержка функции SRIOV для сетевых карточек.
Возможность изменения раскладки клавиатуры в браузере.
Поддержка комбинаций Cmd+a или Ctrl+a для выделения всех ВМ в списке.
Поддержка функций Soft-power и Reset для виртуальных машин, если установлены VMware Tools.
Операции с хостом:
Возможность изменять host acceptance level для установки сторонних пакетов.
Редактирование списка пользователей для исключений режима lockdown mode.
Изменение настроек системного свопа.
Скачать ESXi Embedded Host Client v4 можно по этой ссылке.
У большинства администраторов хотя бы раз была ситуация, когда управляющий сервер VMware vCenter оказывался недоступен. Как правило, этот сервер работает в виртуальной машине, которая может перемещаться между физическими хостами VMware ESXi.
Если вы знаете, где находится vCenter, то нужно зайти на хост ESXi через веб-консоль Embedded Host Client (который у вас должен быть развернут) и запустить/перезапустить ВМ с управляющим сервером. Если же вы не знаете, где именно ваш vCenter был в последний раз, то вам поможет вот эта статья.
Ну а как же повлияет недоступность vCenter на функционирование вашей виртуальной инфраструктуры? Давайте взглянем на картинку:
Зеленым отмечено то, что продолжает работать - собственно, виртуальные машины на хостах ESXi. Оранжевое - это то, что работает, но с некоторыми ограничениями, а красное - то, что совсем не работает.
Начнем с полностью нерабочих компонентов в случае недоступности vCenter:
Централизованное управление инфраструктурой (Management) - тут все очевидно, без vCenter ничего работать не будет.
DRS/Storage DRS - эти сервисы полностью зависят от vCenter, который определяет хосты ESXi и хранилища для миграций, ну и зависят от технологий vMotion/Storage vMotion, которые без vCenter не работают.
vMotion/SVMotion - они не работают, когда vCenter недоступен, так как нужно одновременно видеть все серверы кластера, проверять кучу различных условий на совместимость, доступность и т.п., что может делать только vCenter.
Теперь перейдем к ограниченно доступным функциям:
Fault Tolerance - да, даже без vCenter ваши виртуальные машины будут защищены кластером непрерывной доступности. Но вот если один из узлов ESXi откажет, то новый Secondary-узел уже не будет выбран для виртуальной машины, взявшей на себя нагрузку, так как этот функционал опирается на vCenter.
High Availability (HA) - тут все будет работать, так как настроенный кластер HA функционирует независимо от vCenter, но вот если вы запустите новые ВМ - они уже не будут защищены кластером HA. Кроме того, кластер HA не может быть переконфигурирован без vCenter.
VMware Distributed Switch (vDS) - распределенный виртуальный коммутатор как объект управления на сервере vCenter работать перестанет, однако сетевая коммуникация между виртуальными машинами будет доступна. Но вот если вам потребуется изменить сетевые настройки виртуальной машины, то уже придется прицеплять ее к обычному Standard Switch, так как вся конфигурация vDS доступна для редактирования только с работающим vCenter.
Other products - это сторонние продукты VMware, такие как vRealize Operations и прочие. Тут все зависит от самих продуктов - какие-то опираются на сервисы vCenter, какие-то нет. Но, как правило, без vCenter все довольно плохо с управлением сторонними продуктами, поэтому его нужно как можно скорее поднимать.
Для обеспечения доступности vCenter вы можете сделать следующее:
Защитить ВМ с vCenter технологией HA для рестарта машины на другом хосте ESXi в случае сбоя.
Использовать кластер непрерывной доступности VMware Fault Tolerance (FT) для сервера vCenter.
Как вы знаете, некоторое время назад вышло обновление платформы виртуализации VMware vSphere 6 Update 1, в котором были, в основном, только минорные обновления. Но было и важное - теперь виртуальный модуль VMware vCenter Server Appliance (vCSA) стало возможно обновлять путем монтирования к нему ISO-образа с апдейтом.
Давайте покажем упрощенный процесс обновления через смонтированный образ. Итак, соединимся с хостом vCSA по SSH (если у вас есть отдельный сервер Platform Services Controller, то коннектиться нужно к нему):
Далее скачаем обновление vCenter, в котором есть и обновление vCSA версии 6.0.0 (выберите продукт VC и в разделе VC-6.0.0U1-Appliance скачайтеVMware-vCenter-Server-Appliance-6.0.0.10000-3018521-patch-FP.iso):
Здесь надо пояснить, что это за обновления:
FP (Full patch) - это обновление всех компонентов vCenter, включая полноценные продукты, vCenter, vCSA, VMware Update Manager, PSC и прочее.
TP (Third party patch) - это обновление только отдельных компонентов vCenter.
Скачиваем патч FP (VMware-vCenter-Server-Appliance-6.0.0.10000-3018521-patch-FP.iso), после чего монтируем этот ISO-образ к виртуальной машине vCSA через vSphere Web Client или Embedded Host Client.
Далее возвращаемся к консоли vCSA:
Смонтировать ISO-образ можно также через PowerCLI с помощью следующих команд:
Далее выполняем следующую команду, если вы хотите накатить патчи прямо сейчас:
software-packages install --iso --acceptEulas
Либо патчи можно отправить на стейджинг отстаиваться (то есть пока обновить компоненты, но не устанавливать). Сначала выполняем команду отсылки на стейджинг:
software-packages install --iso --acceptEulas
Далее просматриваем содержимое пакетов:
software-packages list --staged
И устанавливаем апдейт со стейджинга:
software-packages install --staged
Если во время обновления на стейджинг или установки обновления возникли проблемы, вы можете просмотреть логи, выполнив следующие команды:
shell.set –enabled True shell cd /var/log/vmware/applmgmt/ tail software-packaged.log –n 25
Далее размонтируйте ISO-образ от виртуальной машины или сделайте это через PowerCLI следующей командой:
shutdown reboot -r "Updated to vCenter Server 6.0 Update 1"
Теперь откройте веб-консоль vCSA по адресу:
https://<FQDN-or-IP>:5480
И перейдите в раздел Update, где вы можете увидеть актуальную версию продукта:
Кстати, обратите внимание, что возможность проверки обновления в репозитории (Check URL) вернулась, и обновлять vCSA можно прямо отсюда по кнопке "Check Updates".
Продолжаем рассказывать о решении номер 1 для создания программных хранилищ под виртуализацию VMware и Microsoft - StarWind Virtual SAN. Сегодня мы расскажем об альтернативном способе приобретения продукта, который может быть полезен, в основном, сервисным компаниям, которые предоставляют услуги пользователям на базе подписки.
Мы хотим рассказать о двух вариантах использования лицензий StarWind, которые позволяют перенести капитальные затраты (CapEX) в операционные расходы (OpEX) - это важно для провайдера ИТ-услуг, например, IaaS-хостинга виртуальных машин.
Первый вариант - аренда лицензий PaaS (Platform-as-a-Service). В этом случае заказчик платит по мере потребления услуги помесячно. Нет платежа - нет лицензии, тут все просто. StarWind выступает в виде облачной платформы хранения, к сервисам которой у клиента есть "подключение" и которая потребляется по SaaS-модели для клиента.
Второй вариант - лизинг ПО StraWind. В этом случае также есть помесячные платежи, но в результате всех выплат лицензия на ПО остается в собственности клиента, который далее может использовать ее и продлевать подписку на обновления.
Многие из вас знают, что в решении VMware Horizon View есть две полезных возможности, касающихся функций печати из виртуального ПК пользователя - это перенаправление принтеров (Printer redirection) и печать на основе местоположения (Location based printing). Об этих функциях подробно рассказано в документе "Virtual Printing Solutions with View in Horizon 6", а мы изложим тут лишь основные сведения, содержащиеся в нем.
Printer redirection
Эта возможность позволяет перенаправить печать из виртуального ПК к локальному устройству пользователя, с которого он работает, и к которому подключен принтер уже физически. Функция поддерживается не только для Windows-машин, но и для ПК с ОС Linux и Mac OS X. Работает эта фича как для обычных компьютеров, так и для тонких клиентов (поддерживается большинство современных принтеров).
При печати пользователь видит принтер хоста не только в диалоге печати приложения, но и в панели управления. При этом не требуется в виртуальном ПК иметь драйвер принтера - достаточно, чтобы он был установлен на хостовом устройстве.
Перенаправление принтеров полезно в следующих случаях:
в общем случае, когда к физическому ПК пользователя привязан принтер
когда пользователь работает из дома со своим десктопом и хочет что-то распечатать на домашнем принтере
работники филиала печатают на локальных принтерах, в то время, как сами десктопы расположены в датацентре центрального офиса
Схема передачи задания на печать для перенаправления принтера выглядит так:
То есть Horizon Client получает данные в формате EMF от виртуального ПК и передает его уже на хостовом устройстве к драйверу принтера.
Location based printing
Эта фича позволяет пользователям виртуальных ПК печатать на тех принтерах, которые находятся географически ближе к нему, чтобы не бегать, например, на другой этаж офисного здания, чтобы забирать распечатанное, когда есть принтеры поблизости. Правила такой печати определяются системным администратором.
Для функции Location based printing задания печати направляются с виртуального ПК напрямую на принтер, а значит нужно, чтобы на виртуальном десктопе был установлен драйвер этого принтера.
Есть 2 типа правил Location based printing:
IP-based printing - используется IP-адрес принтера для определения правил маппинга принтера к десктопам.
UNC-based printing - используются пути в формате Universal Naming Convention (UNC) для определения правил маппинга принтеров.
Здесь задание на печать передается в рамках следующего рабочего процесса:
Запрос пользователя с хостового устройства через Horizon Client передается к View Agent, который через взаимодействие с приложением передает задание драйверу принтера в гостевой ОС с учетом правил маппинга принтеров, а дальше уже обработанное задание идет на печать.
В зависимости от способа доступа, поддерживаются методы перенаправления принтеров или печать на основе местоположения:
Очевидно, что в нулевом клиенте и в мобильном девайсе нет хостового драйвера принтера, поэтому там и нет поддержки Printer redirection. Ну и то же самое можно сказать про доступ HTML access через браузер - там тоже поддержка отсутствует.
Надо сказать, что и Printer redirection, и Location based printing поддерживаются для следующих моделей доступа пользователей инфраструктуры VDI:
Десктопы View
Десктопы RDSH
Десктопы Windows Server 2008 R2 и Windows Server 2012 R2
Приложения Hosted apps
Ну а о том, как настраивать обе техники печати из виртуальных ПК вы можете прочитать в документе.
Мы уже писали о том, что последней версии решения для виртуализации настольных ПК VMware Horizon View 6.2 есть поддержка режима vGPU. Напомним, что это самая прогрессивная технология NVIDIA для поддержки требовательных к производительности графической подсистемы виртуальных десктопов.
Ранее мы уже писали про режимы Soft 3D, vSGA и vDGA, которые можно применять для виртуальных машин, использующих ресурсы графического адаптера на стороне сервера.
Напомним их:
Soft 3D - рендеринг 3D-картинки без использования адаптера на основе программных техник с использованием памяти сервера.
vDGA - выделение отдельного графического адаптера (GPU) одной виртуальной машине.
vSGA - использование общего графического адаптера несколькими виртуальными машинами.
Режим vSGA выглядит вот так:
Здесь графическая карта представляется виртуальной машине как программный видеодрайвер, а графический ввод-вывод обрабатывается через специальный драйвер в гипервизоре - ESXi driver (VIB-пакет). Команды обрабатываются по принципу "first come - first serve".
Режим vDGA выглядит вот так:
Здесь уже физический GPU назначается виртуальной машине через механизм проброса устройств DirectPath I/O. То есть целый графический адаптер потребляется виртуальной машиной, что совсем неэкономно, но очень производительно.
В этом случае специальный драйвер NVIDIA GPU Driver Package устанавливается внутри виртуальной машины, а сам режим полностью поддерживается в релизах Horizon View 5.3.х и 6.х (то есть это давно уже не превью и не экспериментальная технология). Этот режим работает в графических картах K1 и K2, а также и более свежих адаптерах, о которых речь пойдет ниже.
Режим vGPU выглядит вот так:
То есть встроенный в гипервизор NVIDIA vGPU Manager (это тоже драйвер в виде пакета ESXi VIB) осуществляет управление виртуальными графическими адаптерами vGPU, которые прикрепляются к виртуальным машинам в режиме 1:1. В операционной системе виртуальных ПК также устанавливается GRID Software Driver.
Здесь уже вводится понятие профиля vGPU (Certified NVIDIA vGPU Profiles), который определяет типовую рабочую нагрузку и технические параметры десктопа (максимальное разрешение, объем видеопамяти, число пользователей на физический GPU и т.п.).
vGPU можно применять с первой версией технологии GRID 1.0, которая поддерживается для графических карт K1 и K2:
Но если мы говорим о последней версии технологии GRID 2.0, работающей с адаптерами Tesla M60/M6, то там все устроено несколько иначе. Напомним, что адаптеры Tesla M60 предназначены для Rack/Tower серверов с шиной PCIe, а M6 - для блейд-систем различных вендоров.
Технология NVIDIA GRID 2.0 доступна в трех версиях, которые позволяют распределять ресурсы между пользователями:
Характеристики данных лицензируемых для адаптеров Tesla изданий представлены ниже:
Тут мы видим, что дело уже не только в аппаратных свойствах графической карточки, но и в лицензируемых фичах для соответствующего варианта использования рабочей нагрузки.
Каждый "experience" лицензируется на определенное число пользователей (одновременные подключения) для определенного уровня виртуальных профилей. Поэтому в инфраструктуре GRID 2.0 добавляется еще два вспомогательных компонента: Licensing Manager и GPU Mode Change Utility (она нужна, чтобы перевести адаптер Tesla M60/M6 из режима compute mode в режим graphics mode для работы с соответствующим типом лицензии виртуальных профилей).
Обратите внимание, что поддержка гостевых ОС Linux заявлена только в последних двух типах лицензий.
На данный момент сертификацию драйверов GRID прошло следующее программное обеспечение сторонних вендоров (подробнее об этом тут):
Спецификации карточек Tesla выглядят на сегодняшний день вот так:
Поддержка также разделена на 2 уровня (также прикрепляется к лицензии):
Руководство по развертыванию NVIDIA GRID можно скачать по этой ссылке, ну а в целом про технологию написано тут.
Напомним, что о подходе VMware к контейнеризованным приложениям Docker мы писали вот тут. Вкратце: VMware предлагает на базе Photon OS запускать контейнеры в виртуальных машинах (одна ВМ - одно приложение), а с помощью средств VMFork мгновенно создавать экземпляры таких виртуальных машин по требованию.
Выпущенный на днях Docker Management Pack for vRealize Operations Manager собирает данные о производительности этих контейнеров в вашем окружении Docker, а также предоставляет анализ о возможных трудностях с производительностью. Кроме того, в данном средстве в реальном времени доступна информация об имеющихся проблемах в инфраструктуре Docker (они обозначаются красными квадратиками).
Данный management pack представляет собой плагин к vRealize Operations Manager 6.x. Он отображает взаимосвязи между различными компонентами инфраструктуры Docker (например соотношение между образом и контейнером), а также собирает данные о производительности и свойствах с каждой системы Docker.
Для установки плагина нужно зайти в раздел Administration > Solutions в vRealize Operations Manager и загрузить pak-файл, нажав плюсик:
Скачать VMware vRealize Operations Docker 1.0 Adapter можно по этой ссылке.
Те, из вас, кто пользуется веб-средством vSphere Web Client для управления виртуальной инфраструктурой VMware vSphere, знают, что при логине в окно клиента в самом низу предлагают скачать Client Integration Plugin (CIP):
CIP - это пакет средств от VMware, представляющий собой набор полезных утилит для некоторых административных операций в виртуальной инфраструктуре. Утилиты доступны как для Microsoft Windows, так и для Apple Mac OS X (а скоро будет и поддержка Linux).
Посмотрим на состав этого набора:
ovftool - это отдельная утилита CLI, которую можно использовать для импорта и экспорта виртуальных модулей (Virtual Appliances) в форматах OVF и OVA.
Windows Authentication - позволяет использовать аутентификацию SSPI Windows при логине через vSphere Web Client.
Remote Devices - возможность подключить клиентские устройства (CD-ROM, Floppy, USB и прочие) к виртуальной машине.
File Upload/Download - это вынесенный в отдельную утилиту Datastore browser для загрузки файлов на виртуальные хранилища.
Content Library - операции импорта и экспорта для компонента Content Library.
Client Side Logging/Config - позволяет записывать логи на стороне клиента, а также реализует настройки логирования vSphere Web Client.
Процедура развертывания vSphere Client Integration Plugin выглядит примерно так (видео от версии vSphere 5.5):
Ранее CIP как браузерный плагин использовал модель Netscape Plugin Application Programming Interface (NPAPI), но поскольку в Google Chrome последних версий и прочих браузерах поддержка этой устаревшей модели была окончена, то теперь используется обновленная модель отображения, которая реализована, начиная с Sphere 5.5 Update 3a и vSphere 6.0 Update 1 (поэтому лучше CIP использовать с платформами этих версий или выше).
Более подробно об утилитах CIP рассказано вот тут.
Для тех из вас, кто еще не обновил свою инфраструктуру на последнюю версию VMware vSphere 6, компания VMware приготовила очередной пакет исправлений VMware vSphere 5.5 Update 3b. На самом деле, это просто патч VMware ESXi 5.5 patch ESXi550-201512001, в котором произошли некоторые изменения в плане безопасности, а также исправлены ошибки.
Среди заявленных фич, касающихся security, основная - это отключенный по умолчанию SSL третьей версии (SSLv3). Отключили его (как в клиенте, так и в сервере) потому, что он считается устаревшим, и его поддержка уже не предоставляется в большинстве Enterprise-продуктов (об этом можно почитать в RFC 7568).
Внимание! Обязательно следуйте рекомендованной последовательности обновления продуктов VMware, то есть сначала обновите vCenter до версии 5.5 Update 3b и только потом ESXi 5.5 до версии Update 3b, чтобы избежать проблем с отключением хостов от сервера управления vCenter.
Также помните, что VMware View Composer версии ниже 6.2 не будет работать с хостами ESXi 5.5 Update 3b.
Когда вы выбираете облачного провайдера под проект IaaS, основное внимание уделяется характеристикам самого облака. Вы уточняете время доступности сервисов, гарантированные параметры производительности, возможности расширения набора облачных ресурсов и т. п. Но за любым виртуальным облаком кроется реальное оборудование, установленное в четырех стенах на некой территории. И от надежности всей этой «фоновой» инфраструктуры в значительной степени зависит надежность нового разворачиваемого в облаке сервиса.
Так как облачные вычисления привлекают не только маленькие компании с невысокой зависимостью от ИТ, но и действительно крупные корпорации с полностью «цифровыми» бизнес-направлениями, ко всем компонентам стоит отнестись особенно внимательно. Дело в том, что облачный провайдер часто оперирует характеристиками собственных сервисов, декларируя тот или иной уровень надежности (привычные нам «девятки»). Но даже если предположить, что в цифрах заявленной надежности и производительности нет лукавства, остается открытым вопрос соответствия подобным показателям нижележащей инфраструктуры. Ведь никакое дублирование и кластеризация не помогут вашим облачным виртуальным машинам при перегреве оборудования в машинном зале.
Не стоит забывать и о национальных особенностях ИТ-бизнеса. Далеко не все коммерческие дата-центры имеют официальную сертификацию по классу надежности, и еще меньшее их число подтверждено реальным независимым аудитом. Увы, но все еще встречаются разнообразные «внутренние сертификации», «нам это не нужно, мы уверены» и «заявленный уровень надежности — TIER III+» (с этими плюсами ситуация вообще забавная, но об этом позже).
Чтобы избежать будущих и вполне реальных неприятностей на ровном месте, рекомендуем внимательно подойти к выбору облачного поставщика, самостоятельно проверив характеристики его дата-центров. В конце концов, вы имеете полное право знать, где и как хранится ваша информация и насколько надежен «цифровой фундамент» бизнеса. Далее мы будем говорить преимущественно о самих ЦОД, отложив в сторону особенности облачных провайдеров.
Чем отличается надежность со стороны клиента и владельца дата-центра
Очевидно, что у владельца ЦОД и его клиента совершенно разные цели и ориентиры. Если вы, как будущий заказчик, стремитесь получить максимально качественный и отвечающий требованиям продукт за разумные деньги, то провайдер, скорее всего, пойдет по пути наименьшего сопротивления. И быть бы всем нашим ЦОД максимально примитивными, если бы не требования рынка. Многие заказчики откажутся пользоваться услугами ЦОД без резервных источников питания и дублированной системы охлаждения. А некоторые еще и обратят внимание на географическое расположение и характеристики самого здания с машинным залом.
В то же время можно встретить немало ЦОД, где систему охлаждения проектировали несведущие в вопросе люди, оба «независимых» подвода питания исходят из одной магистральной линии города либо для дизельного генератора не предусмотрено своевременного подвоза топлива. Да что там говорить, мне лично доводилось видеть дата-центр, где холодный коридор был реализован двумя кондиционерами, дующими в некую точку посередине. Очевидно, что температура оборудования в крайних стойках может и не уложиться в ожидаемые пределы при высокой нагрузке.
Что же обычно хочет видеть заказчик при оценке надежности дата-центра:
Непрерывную работу ЦОД не менее определенного значения в год. На этот фактор влияет уровень резервирования всех ключевых узлов (охлаждение, электропитание, класс серверного оборудования).
Соразмерный ожиданиям заказчика уровень гарантированной производительности.
Возможности по защите информации от хищения. Сюда входит скорее риск физического доступа к оборудованию посторонних лиц, то есть речь идет об охране.
Между тем порой упускаются важные и неочевидные моменты, которые могут вылиться в серьезные неприятности:
Юридический статус ЦОД (права собственности, разрешения всех государственных инстанций и прочее).
Наличие всех необходимых контрактов на обслуживание систем и их поддержку при наступлении аварийной ситуации (тот же контракт на подвозку дизельного топлива для генераторов или план проверок всех систем на готовность к отработке аварии).
Возможности работы инженерных систем при нетипичных температурах и погодных аномалиях.
Проектирование инфраструктуры в соответствии с принятыми в отрасли нормами и правилами.
Разумеется, список неполный. Но даже этот перечень заставляет задуматься о существовании множества особенностей и нюансов, которые при проектировании объекта балансируют между стоимостью и возможностями. Дабы упорядочить ситуацию и внести какое-то подобие структуры, в 1993 году в США был основан The Uptime Institute (UTI), который является лидером в области оценки надежности и доступности дата-центров. Uptime Institute признан мировым ИТ-сообществом как независимый аудитор соответствия ЦОД требованиям отказоустойчивости.
UTI
Организация Uptime Institute за время своего существования собрала информацию о тысячах происшествий в дата-центрах по всему миру. Эти данные использовались для создания классификации по уровням готовности Tier Classification. Этот классификатор через некоторое время стал стандартом де-факто и был включен в состав американского стандарта построения центров обработки данных TIA/EIA-942.
Классификатор состоит из четырех уровней (Tier1 — 4), где большее число означает более высокий уровень надежности:
Tier 1 предполагает отсутствие резервирования систем электропитания и охлаждения машинного зала, отсутствие резервирования серверных систем. Фактически инженерная инфраструктура просто должна быть собственной и иметь подстраховку на случай перебоев с электропитанием (генератор). Уровень доступности — 99,671 %, что соответствует примерно 28,8 часам простоев ежегодно.
Tier 2 основывается на Tier 1, но предполагает резервирование всех активных систем. Это уже более надежный класс, который все же допускает около 22 часов простоев в год (99,75 %).
Tier 3 уже может считаться работающим без остановок. На этом уровне обязательно должны быть зарезервированы все инженерные системы (включая пассивные), должны обеспечиваться возможности ремонта и модернизации без остановки сервисов. Tier 3 фактически предполагает постройку второго ЦОД внутри того же здания — дублирующая СКС, подводы электричества, отдельная система охлаждения, у всего серверного оборудования независимые подключения к нескольким источникам питания. Допускается не более 1,6 часа простоев в год (99,98 %);
Tier 4 является дальнейшим развитием третьего уровня и, помимо резервирования всех систем, предполагает сохранение уровня отказоустойчивости даже при аварии. Схема позволяет гарантировать непрерывность работы при любых умышленных или случайных поломках, допуская простой продолжительностью лишь 0,8 часа ежегодно (99,99 %).
Для вашего удобства я собрал отличия уровней надежности в табличку:
Приходите на вебинар, чтобы узнать, как именно можно получить максимальный эффект от использования All-Flash хранилищ серверов хранения в сочетании с виртуализацией и проприетарной высокопроизводительной файловой системой LSFS от компании StarWind. Ребята действительно очень далеко продвинулись в этом плане.
Как вы знаете, у компании VMware есть средство для комплексного мониторинга и решения проблем в виртуальной среде vRealize Operations. Также в решении для создания инфраструктуры виртуальных ПК предприятия VMware Horizon View (еще с версии 6.0) есть поддержка опубликованных приложений на серверах RDS Hosted Apps.
Ну и логично, что у VMware есть решение vRealize Operations for Published Applications, которое поддерживает мониторинг инфраструктуры доставки приложений через механизм RDS Hosted Apps. На днях вышла обновленная версия этого продукта - vRealize Operations for Published Applications 6.2 одновременно с основным релизом Operations 6.2, с поддержкой не только приложений опубликованных, через RDS, но и продуктов Citrix XenApp и XenDesktop.
Основные новые возможности vRealize Operations for Published Applications 6.2:
Поддержка последних версий Citrix XenDesktop and XenApp 7.6 - функции мониторинга и отчетности теперь доступны для инфраструктуры виртуализации и доставки приложений и десктопов, созданных на данных платформах.
Application and Usage Reports - готовые шаблоны отчетов, которые позволяют администраторам приложений определить потребление ресурсов приложениями, пиковые нагрузки, параметры сессий пользователей на серверных ресурсах, а также учитывать потребление пользователями лицензий отдельных приложений.
Proactive User Experience Monitoring - новый дэшборд "User Experience", который постоянно мониторит vCPU, vRAM и vDisk, чтобы с помощью карты heat map оповестить администратора о том, что некоторые пользователи испытывают проблемы при работе с их приложениями.
Reduced Time to Resolve - новые метрики сессии, которые помогают устранять проблемы: длительность процесса логина, сортировка по времени логина сессий, использование системных ресурсов, а также ICA Round Trip Time для приложений Citrix.
Windows 10 support - теперь Windows 10 поддерживается для мониторинга, как для VMware Horizon View, так и для решений XenDesktop/XenApp.
Алерты для Citrix Storefront, PVS Server, Citrix License Server и Citrix Database Server - теперь все эти компоненты поддерживаются в рамках общей процедуры мониторинга доступности компонентов инфраструктры виртуальных ПК и приложений.
Мониторинг лицензий Citrix License Server - теперь можно учитывать лицензии, считаемые этим продуктом.
Improved Logon Breakdown metrics to meet SLAs - дэшборд "Session Details" теперь показывает метрику длительность процесса логина для самых тормозных ПК.
Connection and machine failure data - эта новая метрика мониторит общее число неудачных соединений и стартов машин на ферме Citrix XenDesktop.
Более подробно о новых функциях решения vRealize Operations for Published Applications 6.2 написано в Release Notes. Напомним, что это решение включено в состав продукта vRealize Operations for Horizon, который можно скачать по этой ссылке.
Компания VMware на днях выпустила обновление своей платформы виртуализации для Mac OS - VMware Fusion 8.1. Напомним, что о прошлой версии VMware Fusion 8 мы писали вот тут.
Интересно, что эта версия продукта не предоставляет новых возможностей, но несет в себе достаточно много исправлений ошибок, что означает, что их в восьмой версии было немало (вообще говоря, в последнее время VMware довольно часто выпускает продукты с серьезными багами).
От себя скажу, что для меня лично была очень актуальна ошибка с задержками при работе в Excel - пишут что был "one-second delay", однако ничего подобного - у меня вся машина фризилась секунд на 20-30, пока я не обновил Fusion.
Итак, какие багофиксы были сделаны:
Исправления ошибок для упрощенного процесса инсталляции гостевых ОС из ISO-образов Windows 10 и Windows server 2012 R2.
Исправлена ошибка с неработающим обратным DNS lookup в виртуальной машине, когла на Mac-хосте установлен сервер dnsmasq.
Исправление ошибки с крэшем машины при отключении внешнего монитора от Mac, когда Fusion работает в полноэкранном режиме.
Исправлена ошибка при зависании машины на несколько секунд при работе в Microsoft Excel.
Исправлена ошибка, когда использование USB-устройств на OS X 10.11 могло завалить виртуальную машину.
Исправлена ошибка, когда хостовая и гостевая раскладки клавиатуры (non-English) отличались при использовании VNC.
Исправлена ошибка подключения хоста к гостевой ОС, когда USB Attached SCSI (UAS) присоединен к порту USB 3.0 на Mac OS X 10.9 или более поздних версий.
Исправлено поведение, когда копирование большого файла с USB могло приводить к замораживанию процесса и в итоге его прерыванию по таймауту.
Посмотрите на список: большинство из этого - реально серьезные вещи. Что-то VMware в последнее время не радует своим подходом к тестированию продуктов.
Обновление VMware Fusion 8.1 бесплатно для всех пользователей восьмой версии, скачать его можно по этой ссылке.
На блогах VMware появился интересный пост про производительность виртуальных машин, которые "растянуты" по ресурсам на весь физический сервер, на котором они запущены. В частности, в посте речь идет о сервере баз данных, от которого требуется максимальная производительность в числе транзакций в секунду (см. наш похожий пост о производительности облачного MS SQL здесь).
В данном случае речь идет о виртуализации БД с типом нагрузки OLTP, то есть обработка небольших транзакций в реальном времени. Для тестирования использовался профиль Order-Entry, который основан на базе бенчмарка TPC-C. Результаты подробно описаны в открытом документе "Virtualizing Performance Critical Database Applications in VMware vSphere 6.0", а здесь мы приведем основные выдержки.
Сводная таблица потерь на виртуализацию:
Метрика
Нативное исполнение нагрузки
Виртуальная машина
Пропускная способность транзакций в секунду
66.5K
59.5K
Средняя загрузка логических процессоров (72 штуки)
84.7%
85.1%
Число операций ввода-вывода (Disk IOPS)
173K
155K
Пропускная способность ввода-вывода дисковой подсистемы (Disk Megabytes/second)
929MB/s
831MB/s
Передача пакетов по сети в секунду
71K/s receive
71K/s send
63K/s receive
64K/s send
Пропускная способность сети в секунду
15MB/s receive
36MB/s send
13MB/s receive
32MB/s send
А вот так выглядит график итогового тестирования (кликабельно):
Для платформы VMware ESXi 5.1 сравнивалась производительность на процессоре микроархитектуры Westmere, а для ESXi 6.0 - на процессорах Haswell.
Результаты, выраженные в числе транзакций в секунду, вы видите на картинке. Интересно заметить, что ESXi версии 6.0 всерьез прибавил по сравнению с прошлой версией в плане уменьшения потерь на накладные расходы на виртуализацию.
А вот так выглядят усредненные значения для версий ESXi в сравнении друг с другом по отношению к запуску нагрузки на нативной платформе:
Ну и несложно догадаться, что исследуемая база данных - это Oracle. Остальное читайте в интереснейшем документе.

 RSS
RSS






















 «За выдающийся вклад технического партнера в продвижение серверных систем NetApp» — такую
«За выдающийся вклад технического партнера в продвижение серверных систем NetApp» — такую 




























































{kind=link}

